✌️Mani avanti: di post come questi ne trovi a dozzine online, ma questo l’ho pensato in italiano per chi è alle prime armi con l’intelligenza artificiale o per chi vuole solo capire cosa sono e come funzionano i sistemi RAG (Retrieval-Augmented Generation).
Partiamo.
In un’era in cui la privacy è fondamentale (sarà vero??), non è consigliabile “passare” i propri dati su sistemi online, per questo motivo avere un proprio Large Language Model (LLM) -una specie di chatGPT- installato in locale e con capacità “aumentate” potrebbe essere una soluzione “non definitiva” ma sicuramente in grado di garantire maggiore sicurezza e accuratezza ad aziende e individui.
L’obiettivo di questo contenuto è duplice:
1 – Aiutarti a creare un sistema RAG, simile a chatGPT (basato su un modello open source), ma installato sul tuo computer, in grado di interagire con le tue fonti (ricerche, documenti, presentazioni, elenchi) e soprattutto gratuito.
2- Spiegarti, senza dover mettere mano al codice, come funzionano i sistemi RAG nel dominio dell’intelligenza artificiale.
Utilizzerò Ollama, Python 3 con qualche libreria e ChromaDB (non spaventarti ti spiegherò di cosa si tratta), con l’obiettivo di far girare tutto in locale sul tuo sistema. Ovviamente chi si cimenterà con il tutorial potrà usare l’editor di codice sorgente preferito (Visual Studio Code, PyCharm, Jupyter Notebook o un semplice Notepad ++). Un po’ di pazienza e qualche ricerca su internet ti aiuteranno a completare il tutorial.
In questo progetto terrò sempre al centro 5 obiettivi fondamentali, deciderai tu quale sarà per te più importante e su quale vorrai approfondire o alzare l’asticella.
Controllo sull’elaborazione dei dati: quando ospiti un LLM in locale, hai la possibilità di gestire ed elaborare i tuoi dati come meglio preferisci. Questo include l’incorporamento dei tuoi dati riservati in un tuo archivio vettoriale ChromaDB in modo da garantire che l’elaborazione dei dati stessi soddisfi i requisiti che hai scelto tu per il tuo sistema.
Personalizzazione: ospitare in locale la tua applicazione RAG (Retrieval-Augmented Generation) significa avere il controllo completo sulla configurazione e sulla personalizzazione. Puoi mettere a punto il modello per adattarlo alle tue esigenze specifiche senza fare affidamento su servizi esterni.
Privacy: configurando il tuo modello LLM in locale, eviti i rischi associati all’invio di dati sensibili su Internet. Pensa a quanto sia importante questo aspetto per le aziende che gestiscono informazioni riservate. L’addestramento del tuo modello con dati privati a livello locale garantisce infatti che i tuoi dati rimangano sotto il tuo, e solo tuo, controllo.
Sicurezza: l’utilizzo di modelli LLM di terze parti può esporre i tuoi dati a potenziali violazioni e usi impropri. Una distribuzione locale mitiga questi rischi mantenendo i dati di “addestramento” come documenti PDF o immagini, all’interno di un tuo ambiente protetto e sicuro.
Continuità offline: se esegui il tuo chatbot in locale sei indipendente (o quasi) da una connessione e questo ti garantisce continuità anche quando non “c’è internet”.
Cos’è un Retrieval-Augmented Generation (RAG)
La Retrieval-Augmented Generation (RAG) è una tecnica avanzata nell’ambito dell’intelligenza artificiale, ideata per superare i limiti dei Large Language Model (LLM) come GPT-3, BERT e T5, che, pur essendo capaci di generare testi naturali e realistici, dipendono esclusivamente dai dati di addestramento, spesso incompleti o nella peggiore delle ipotesi, obsoleti.
Introdotta dal paper del 2020 di Patrick Lewis e altri dal titolo “Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks“, la RAG combina le capacità generative dei LLM con la possibilità di reperire informazioni aggiornate da fonti esterne, producendo testi più accurati, pertinenti e informativi, migliorando notevolmente la qualità del contenuto generato.
Per farla breve, una RAG aiuta il modello LLM a “cercare” informazioni esterne per migliorare le sue risposte.
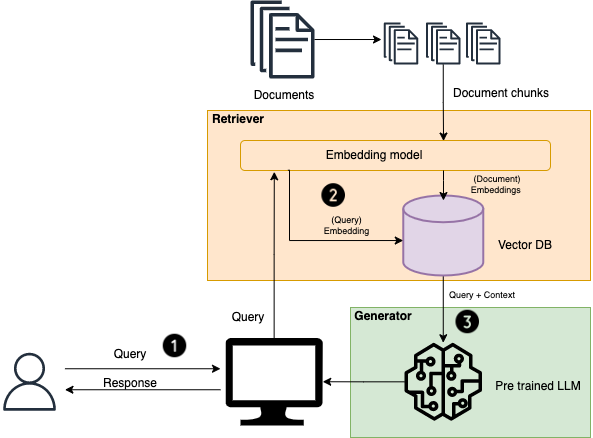
Come funziona la RAG?
- Input della query: L’utente inserisce una domanda o una query.
- Recupero dei documenti: Il sistema utilizza la query per cercare in una base di conoscenza esterna, recuperando i documenti o i frammenti di informazione più rilevanti.
- Generazione della risposta: Il modello generativo elabora le informazioni recuperate, integrandole con la propria conoscenza per generare una risposta dettagliata e accurata.
- Output: La risposta finale, arricchita con dettagli specifici e rilevanti dalla base di conoscenza, viene presentata all’utente.
Benefici della RAG
- Maggiore accuratezza: Utilizzando dati esterni, i modelli RAG possono fornire risposte più precise e dettagliate, specialmente per query specifiche che necessitano di risposte molto precise e aggiornate. Hai presente quando chiedi qualcosa di molto specifico ad un esperto di dominio?
- Rilevanza contestuale: La componente di recupero assicura che la risposta generata sia basata su informazioni rilevanti e aggiornate, migliorando la qualità complessiva della risposta.
- Scalabilità: I sistemi RAG possono essere facilmente scalati per incorporare grandi quantità di dati, permettendo di gestire una vasta gamma di query e argomenti.
- Flessibilità: Questi modelli possono essere adattati a vari domini semplicemente aggiornando o espandendo la base di conoscenza esterna, rendendoli altamente versatili.
Perché usare la RAG in locale?
- Privacy e sicurezza: Eseguire un modello RAG localmente garantisce che i dati sensibili rimangano sicuri e privati, poiché non è necessario inviarli a server esterni.
- Personalizzazione: È possibile personalizzare i processi di recupero e generazione per soddisfare le proprie esigenze specifiche, includendo l’integrazione di fonti di dati proprietarie.
- Indipendenza: Una configurazione locale assicura che il sistema rimanga operativo anche senza connettività internet, fornendo un servizio costante e affidabile.
Impostando un’applicazione RAG locale con strumenti come Ollama, Python e ChromaDB, è possibile sfruttare i vantaggi dei modelli linguistici avanzati mantenendo il controllo sui propri dati e sulle opzioni di personalizzazione.
GPU
L’esecuzione di modelli linguistici di grandi dimensioni (LLM), come quelli utilizzati nella Retrieval-Augmented Generation (RAG), richiede una notevole potenza di calcolo. Un componente chiave che consente l’elaborazione efficiente di questi modelli è l’unità di elaborazione grafica (GPU), una scheda grafica. Ecco perché le GPU sono essenziali per questa attività e con la “bolla” dell’intelligenza artificiale il titolo di NVIDIA Corp (casa che produce GPU) è schizzato alle stelle.
Cos’è una GPU?
Una GPU è un processore specializzato progettato per accelerare il rendering di immagini e video. A differenza delle unità di elaborazione centrale (CPU), che sono ottimizzate per attività di elaborazione sequenziale, le GPU eccellono nell’elaborazione parallela, rendendole particolarmente adatte ai complessi calcoli matematici richiesti dai modelli di machine learning e deep learning.
Perché le GPU sono importanti per i LLM
Potenza di elaborazione parallela: le GPU possono gestire migliaia di operazioni contemporaneamente, accelerando significativamente attività come l’addestramento e l’inferenza nei LLM. Questo parallelismo è cruciale per i pesanti carichi computazionali associati all’elaborazione di grandi set di dati e alla generazione di risposte in tempo reale.
Efficienza nella gestione di modelli di grandi dimensioni: i LLM come quelli utilizzati in RAG richiedono notevoli risorse di memoria e di calcolo. Le GPU sono dotate di memoria a larghezza di banda elevata (HBM) e core multipli, che le rendono capaci di gestire le moltiplicazioni di matrici su larga scala e le operazioni tensoriali necessarie per questi modelli.
Incorporamento e recupero dei dati più rapidi: in una configurazione RAG locale, incorporare i dati in un archivio vettoriale come ChromaDB e recuperare rapidamente i documenti pertinenti è essenziale per le prestazioni. Le GPU ad alte prestazioni possono accelerare questi processi, garantendo che il tuo chatbot risponda in modo rapido e accurato.
Tempi di addestramento migliorati: l’addestramento di un LLM comporta la regolazione di milioni (o addirittura miliardi) di parametri. Le GPU possono ridurre drasticamente il tempo richiesto per questa fase di addestramento rispetto alle CPU, consentendo aggiornamenti e perfezionamenti più frequenti al tuo modello.
Scegliere la GPU giusta
Quando si configura un LLM locale, la scelta della GPU può avere un impatto significativo sulle prestazioni. Ecco alcuni fattori da considerare:
Capacità di memoria: i modelli più grandi richiedono più memoria GPU. Cerca GPU con VRAM (RAM video) elevata per ospitare set di dati estesi e parametri del modello.
Capacità di elaborazione: maggiore è il numero di CUDA core di una GPU, migliore sarà la sua capacità di gestire le attività di elaborazione parallela. Le GPU con capacità di elaborazione più elevate sono più efficienti per le attività di deep learning.
Larghezza di banda: una maggiore larghezza di banda della memoria consente un trasferimento dati più rapido tra la GPU e la sua memoria, migliorando la velocità di elaborazione complessiva.
👉Per fare un esempio, per Llama-2 con 7 miliardi di parametri può bastare una GPU con 6 GB di VRAM, mentre per la versione da 70 miliardi è raccomandato avere due GPU per un totale di 48 GB.
Cassetta degli attrezzi
Prima di approfondire ti anticipo che installeremo:
Python 3: Python è un linguaggio di programmazione versatile che utilizzerai per scrivere il codice per la tua app RAG.
ChromaDB: un database vettoriale che memorizzerà e gestirà gli incorporamenti dei nostri dati.
Ollama: per scaricare e servire LLM personalizzati nel nostro computer locale.
Come modelli ho usato Mistral e Gemma ma puoi scegliere tu il modello open source che meglio performa per le tue esigenze. Mistral, che troverai richiamato nel tutorial è distribuito con licenza open source Apache 2.0, che permette un ampio utilizzo del modello, la modifica e la ridistribuzione.
Ci serviranno almeno 8 GB liberi sul computer ed una scheda grafica con memoria dedicata di almeno 8 GB (incrociamo le dita).
Ci sono un sacco di siti che fanno analisi di benchmark su LLM io ho usato questo anche se devo avvertirti che tutte le analisi di performance in questo settore vanno sempre prese con cautela perchè rischiano di diventare una manifestazione della legge di Goodhart.
Quando una misura diventa un obiettivo, cessa di essere una buona misura
Charles Goodhart
Ok partiamo! Se hai già un po’ di dimestichezza puoi fare tutto il progetto in Visual Studio Code.
Step 1 – Installiamo Python
Passaggio 1: installa Python 3 e configura il tuo ambiente
Per installare e configurare il nostro ambiente Python 3, segui questi passaggi: Scarica e configura Python 3 sul tuo computer.
Entra nel prompt dei comandi (su windows digita cmd nel campo “cerca” della barra delle applicazioni)e verifica che sia tutto installato correttamente, alla data di redazione di questo tutorial io ho installato la versione 3.12.2 di python.
👉In tutto il tutorial ti presenterò i comandi con simbolo $ che è una convenzione comunemente utilizzata nella documentazione per indicare il prompt della riga di comando. Non deve essere digitato quando si eseguono i comandi. Per verificare di aver installato completamente Python digita:
$ python3 --version
# Python 3.12.2Passaggio 2: sempre da prompt dei comandi crea la cartella sul tuo computer in cui “vivrà” la tua RAG app. Ad esempio RAGnetto-project

$ mkdir RAGnetto-project
$ cd RAGnetto-projectPassaggio 3: Crea un ambiente virtuale.
Si tratta di un ambiente isolato sul tuo computer che consente di gestire in modo separato le dipendenze e le configurazioni di Python per diversi progetti e ti permette di gestore eventuali librerie necessarie solo per un determinato progetto. Insomma è un passaggio utile perché evita conflitti tra le versioni di librerie Python e soprattutto ti permette di “isolare” il progetto senza problemi.
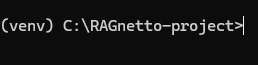
$ python -m venv venvPassaggio 4: attiva l’ambiente virtuale.
Il comando da eseguire per attivare l’ambiente virtuale dipende dal sistema operativo:
Unix/Linux/macOS:
$ source venv/bin/activateWindows:
venv\Scripts\activateA questo punto dovresti vedere un (venv) nel prompt comandi prima del nome della cartella nella sua destinazione:
Step 2: Installa ChromaDB, LangChain, Flask e altre dipendenze
Installa ChromaDB usando pip.
Non ti spaventare, pip è il modo più semplice da prompt dei comandi per installare librerie in python. Le librerie sono parti “pre-compilate” e “verificate” da sviluppatori esperti che possono essere di grande aiuto per chi è alle prime armi in python.
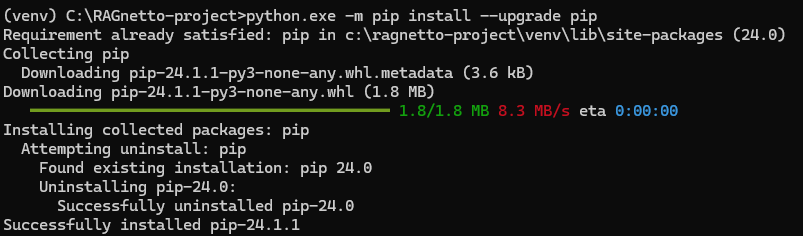
Passaggio 1: Installa o aggiorna pip. Senza pip non puoi eseguire i passaggi successivi.
$ python.exe -m pip install --upgrade pipNel mio caso ad esempio avevo già installato pip ma il sistema ha trovato ed installato una versione più recente. Ricordati che hai bisogno di una connessione ad internet per poter scaricare le librerie.
Passaggio 2: Installa Cromedb
$ pip install --q chromadb
Passaggio 3: Installa i pacchetti Langchain
I grandi modelli linguistici (LLM) eccellono nel rispondere a domande generiche, ma incontrano difficoltà quando si tratta di contesti specifici non precedentemente addestrati. I “prompt” sono domande utilizzate per ottenere risposte dai LLM: per esempio, un LLM può stimare il costo di un computer, ma non può fornire il prezzo di un modello specifico venduto da un’azienda.
Per superare queste limitazioni, si devono integrare i LLM con dati interni dell’organizzazione e applicare una progettazione di prompt. Questa pratica permette a un data scientist di ottimizzare gli input per il modello generativo, definendoli con una struttura e un contesto specifici.
LangChain semplifica i processi intermedi nello sviluppo di applicazioni basate su dati, migliorando l’efficienza nella progettazione dei prompt., facilitando enormemente lo sviluppo di applicazioni come la nostra RAGnetto app.
Ok, bando alle chiacchere e installiamo i pacchetti LangChain che ci interessano. In particolare unstructured e text-splitters. Inoltre installiamo anche tutti i documenti correlati a unstructured.
$ pip install --q unstructured langchain langchain-text-splitters
$ pip install --q "unstructured[all-docs]"
👉Avrai notato che con in venv attivo non ottieni messaggi di conferma dal prompt dei comandi. Non ti preoccupare nella cartella C:\RAGnetto-project\venv\Lib\site-packages hai tutti i pacchetti installati.
👉 Se vuoi approfondire le singole librerie ti consiglio di navigare un sito che fa da indice di tutte le librerie di Python si tratta di https://pypi.org/ (Python Package Index), funziona un po’ come un browser.
Passaggio 4: Installa Flask per servire la tua app come servizio HTTP
Flask è un framework leggero per applicazioni web scritto in Python. È progettato per essere semplice da usare e flessibile, consentendo agli sviluppatori di creare rapidamente applicazioni web senza doversi preoccupare di complessi dettagli di configurazione. Flask supporta la gestione delle richieste HTTP, la gestione delle sessioni, il routing e molte altre funzionalità essenziali per lo sviluppo di applicazioni web. È ampiamente utilizzato per la creazione di API web, backend per siti web e servizi web. Io sono un fan della prima ora di Flask e Django (alternativa più complessa).
$ pip install --q flaskPassaggio 5: installiamo langchain_community
$ pip install pip install langchain_communityStep 3: Installa Ollama
Per installare Ollama, segui questi passaggi:
Passaggio 1: vai alla pagina di download di Ollama, scarica il programma di installazione per il tuo sistema operativo.
Passaggio 2: A priti un nuovo prompt dei comandi (non venv per capirci poichè è un ambiente isolato mentre noi abbiamo installato Ollama a livello centrale). Verifica l’installazione di Ollama eseguendo:
$ ollama --version
# ollama version is 0.1.48
Passaggio 3: Scegli il modello LLM di cui hai bisogno (ovviamente deve essere open source). Ad esempio qui ho utilizzato Mistral
$ ollama pull mistral
👉Attenzione, dovrai avere quale GB libero sulla tua macchina… 😎

E’ il momento di fare una piccola pausa mentre il sistema scarica 4.1 GB di modello.

Passaggio 4: Scegli e scarica un modello di incorporamento del testo. Ad esempio, io ho utilizzato Nomic Embed Text
Come alternativa a Nomic qualora volessi provarli ti segnalo anche mxbai_embed_large e all_minilm. A mio avviso Nomic performa meglio per ora.
$ ollama pull nomic-embed-text
👉 Utilizzare un modello di text embedding (incorporazione del testo) serve per creare una rappresentazione numerica di parole o frasi in modo che possano essere utilizzate all’interno di modelli di machine learning o altri algoritmi che richiedono dati strutturati. Ricordati che le macchine tendenzialmente “danno i numeri” attraverso cui incorporano il testo.
Passaggio 5: Esegui i modelli Ollama
$ ollama serveStep 4: costruisci l’app RAG
Ok, è quasi fatta! Ora che hai configurato il tuo ambiente con Python, Ollama, ChromaDB e le altre dipendenze è il momento di creare la tua app RAG locale personalizzata. In questa sezione torniamo sul codice Python e vediamo come strutturare la tua applicazione. Se vuoi puoi usare Visual Studio Code (VSC) per creare i file e la struttura di progetto. Ricordati di attivare il venv (ambiente virtuale, vedi sopra) da Terminale in VSC avendo cura prima di disattivarlo qualora fosse attivo altrove.
Per disattivare un venv basta solo digitare:
$ deactivatePer riattivare in venv guarda sopra al “Passaggio 4: attiva l’ambiente virtuale“
Passaggio 1: app.py
Questo è il file principale dell’applicazione Flask. Definisce i percorsi per incorporare i file nel database vettoriale e recuperare la risposta dal modello. In VSC basta entrare nella cartella di progetto e creare un nuovo file .py e ricopiare quanto indicato qui sotto per ciascun file.
Ecco il codice per il file app.py
import os
from dotenv import load_dotenv
load_dotenv()
from flask import Flask, request, jsonify
from embed import embed
from query import query
from get_vector_db import get_vector_db
TEMP_FOLDER = os.getenv('TEMP_FOLDER', './_temp')
os.makedirs(TEMP_FOLDER, exist_ok=True)
app = Flask(__name__)
@app.route('/embed', methods=['POST'])
def route_embed():
if 'file' not in request.files:
return jsonify({"error": "Nessuna parte del file"}), 400
file = request.files['file']
if file.filename == '':
return jsonify({"error": "Nessun file selezionato"}), 400
embedded = embed(file)
if embedded:
return jsonify({"message": "File caricato con successo"}), 200
return jsonify({"error": "Caricamento del file non riuscita"}), 400
@app.route('/query', methods=['POST'])
def route_query():
data = request.get_json()
response = query(data.get('query'))
if response:
return jsonify({"message": response}), 200
return jsonify({"error": "Qualcosa è andato storto"}), 400
if __name__ == '__main__':
app.run(host="0.0.0.0", port=8080, debug=True)Passaggio 2: embed.py
Questo file incorpora il modulo che gestisce il processo di incorporamento, incluso il salvataggio dei file caricati, il caricamento e la suddivisione dei dati e l’aggiunta di documenti al database vettoriale.
import os
from datetime import datetime
from werkzeug.utils import secure_filename
from langchain_community.document_loaders import UnstructuredPDFLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
from get_vector_db import get_vector_db
TEMP_FOLDER = os.getenv('TEMP_FOLDER', './_temp')
# Funzione per verificare se il file caricato è consentito (solo file PDF)
def allowed_file(filename):
return '.' in filename and filename.rsplit('.', 1)[1].lower() in {'pdf'}
# Funzione per salvare il file caricato nella cartella temporanea
def save_file(file):
# Save the uploaded file with a secure filename and return the file path
ct = datetime.now()
ts = ct.timestamp()
filename = str(ts) + "_" + secure_filename(file.filename)
file_path = os.path.join(TEMP_FOLDER, filename)
file.save(file_path)
return file_path
# Funzione per caricare e dividere i dati dal file PDF
def load_and_split_data(file_path):
# Load the PDF file and split the data into chunks
loader = UnstructuredPDFLoader(file_path=file_path)
data = loader.load()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=7500, chunk_overlap=100)
chunks = text_splitter.split_documents(data)
return chunks
# Funzione principale per gestire il processo di embedding (incoporamento)
def embed(file):
# Controlla se il file è valido, salvalo, carica e dividi i dati, aggiungi al database e rimuovi il file temporaneo
if file.filename != '' and file and allowed_file(file.filename):
file_path = save_file(file)
chunks = load_and_split_data(file_path)
db = get_vector_db()
db.add_documents(chunks)
db.persist()
os.remove(file_path)
return True
return FalsePassaggio 3: query.py
Questo file contiene il modulo che elabora le query degli utenti generando più versioni della query, recuperando documenti rilevanti e fornendo risposte in base al contesto.
import os
from langchain_community.chat_models import ChatOllama
from langchain.prompts import ChatPromptTemplate, PromptTemplate
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough
from langchain.retrievers.multi_query import MultiQueryRetriever
from get_vector_db import get_vector_db
LLM_MODEL = os.getenv('LLM_MODEL', 'mistral')
# Funzione per ottenere modelli di prompt per generare domande alternative e rispondere in base al contesto
def get_prompt():
QUERY_PROMPT = PromptTemplate(
input_variables=["question"],
template="""You are an AI language model assistant. Your task is to generate five different versions of the given user question to retrieve relevant documents from a vector database. By generating multiple perspectives on the user question, your goal is to help the user overcome some of the limitations of the distance-based similarity search. Provide these alternative questions separated by newlines.
Original question: {question}""",
)
template = """Answer the question based ONLY on the following context:
{context}
Question: {question}
"""
prompt = ChatPromptTemplate.from_template(template)
return QUERY_PROMPT, prompt
# Funzione principale per gestire il processo di query
def query(input):
if input:
# Inizializza il modello linguistico con il nome del modello specificato
llm = ChatOllama(model=LLM_MODEL)
# Ottieni l'istanza del database vettoriale
db = get_vector_db()
# Ottieni i modelli di prompt
QUERY_PROMPT, prompt = get_prompt()
# Configura il retriever per generare più query utilizzando il modello linguistico e la richiesta di query prompt
retriever = MultiQueryRetriever.from_llm(
db.as_retriever(),
llm,
prompt=QUERY_PROMPT
)
# Definire la catena di elaborazione per recuperare il contesto, generare la risposta e analizzare l'output
chain = (
{"context": retriever, "question": RunnablePassthrough()}
| prompt
| llm
| StrOutputParser()
)
response = chain.invoke(input)
return response
return NonePassaggio4: get_vector_db.py
Questo file contiene il modulo che serve per inizializzare e restituire l’istanza del database vettoriale utilizzata per archiviare e recuperare gli incorporamenti di documenti.
import os
from langchain_community.embeddings import OllamaEmbeddings
from langchain_community.vectorstores.chroma import Chroma
CHROMA_PATH = os.getenv('CHROMA_PATH', 'chroma')
COLLECTION_NAME = os.getenv('COLLECTION_NAME', 'RAGnetto-project')
TEXT_EMBEDDING_MODEL = os.getenv('TEXT_EMBEDDING_MODEL', 'nomic-embed-text')
def get_vector_db():
embedding = OllamaEmbeddings(model=TEXT_EMBEDDING_MODEL,show_progress=True)
db = Chroma(
collection_name=COLLECTION_NAME,
persist_directory=CHROMA_PATH,
embedding_function=embedding
)
return dbStep 4: lancia la tua RAG app!
Passaggio 1: Crea un file .env per archiviare le variabili di ambiente. Ricordati di mettere nella COLLECTION_NAME il nome della tua cartella di progetto.
TEMP_FOLDER = './_temp'
CHROMA_PATH = 'chroma'
COLLECTION_NAME = 'RAGnetto-project'
LLM_MODEL = 'mistral'
TEXT_EMBEDDING_MODEL = 'nomic-embed-text'Passaggio2: Esegui il file app.py per avviare il server dell’applicazione.
$ python app.pyPassaggio 3: Una volta che il server è in esecuzione, puoi iniziare a effettuare richieste a diversi endpoint.
Comando di esempio per incorporare un file PDF (ad esempio in questo caso chiedo di caricare il mio curriculum.pdf)
$ curl --request POST \
--url http://localhost:8080/embed \
--header 'Content-Type: multipart/form-data' \
--form file=@/Users/ilcomputerdimax/Documents/Massimiliano-Vurro_CV2024.pdf
Se tutto ha funzionato dovresti ricevere questa risposta dal server (come avevamo definito nel file app.py):
# Response
{
"message": "File caricato con successo"
}A questo punto posso chiedere al sistema qualcosa sul PDF caricato.
$ curl --request POST \
--url http://localhost:8080/query \
--header 'Content-Type: application/json' \
--data '{ "query": "Who is Massimiliano?" }'
# Response
{
"message": "Massimiliano is a senior consultant specializing in web and applied AI development for B2B, with a strong background in compliance and standardization. He is the founder of multiple AI software start-ups and has held various management roles across several fields, including machinery, broadcasting TV, construction, IT, and edutech. His expertise includes business design, board advisory, and implementing exponential technologies to enhance people's quality of life and promote environmental sustainability."
}Considerazioni e suggerimenti.
1- Usa Visual Studio Code per tutto il progetto se hai problemi o poca dimestichezza con il terminale dei comandi e con l’attivazione dell’ambiente virtuale.
2- Per le cURL puoi usare REST (gratuito) ed un file http in cui copi esattamente il testo della cURL in Visual Studio Code (VSC), qui c’è un bel tutorial, personalmente preferisco Postman che è più fluido quando hai già il server avviato in VSC.
3- Per la UI (interfaccia utente) e per semplificare le cURL, pubblicherò il sequel di questo tutorial magari usando proprio una RAG per il design di interfaccia.
Spero questo post ti sia stato utile!